Big Data is the new Buzz work connecting the new trends of data analytics. Data management has shifted its focus from an important competency to a critical differentiator that can determine market winners. So to run along with latest trends check out this course to understand basics of Big Data.
Big Data refers to technologies and initiatives that involve data that is too diverse, fast-changing or massive for conventional technologies, skills and infra- structure to address efficiently. Said differently, the volume, velocity or variety of data is too great.
This course is intended for people who wants to know what is big data.
The course covers what is big data, How hadoop supports concepts of Big Data and how different components like Pig, Hive,MapReduce of hadoop support large sets of data Analytics.
Objective :
The Big Data Hadoop Training Courses are proposed to give you all around learning of the Big Data framework using Hadoop and Spark, including YARN, HDFS and MapReduce. You will be able to learn how to use Pig, Hive, and Impala to practice and examine tremendous datasets stored in the HDFS, and use Sqoop and Flume for data ingestion. You will expert consistent data processing of using Spark, consolidating valuable programming in Spark, understanding parallel processing in Spark, completing Spark applications and using Spark RDD streamlining approaches.
Pre requisites:
Hadoop is developed by Apache and it is basically done using java. So it would be better if we have some basic knowledge about Java. it need not required that you need to be an expert in Java in order to learn Hadoop.
There are some alternate ideas to get knowledge on Scala, Python etc instead of Java in their environment.
Duration :
40hrs
Introduction to Hadoop and Big Data:
- What is Big Data?
- What are the challenges for processing big data?
- What technologies support big data?
- What is Hadoop?
- Why Hadoop?
- History of Hadoop
- Use cases of Hadoop
- RDBMS vs Hadoop
- When to use and when not to use Hadoop
- Ecosystem tour
- Vendor comparison
- Hardware Recommendations & Statistics
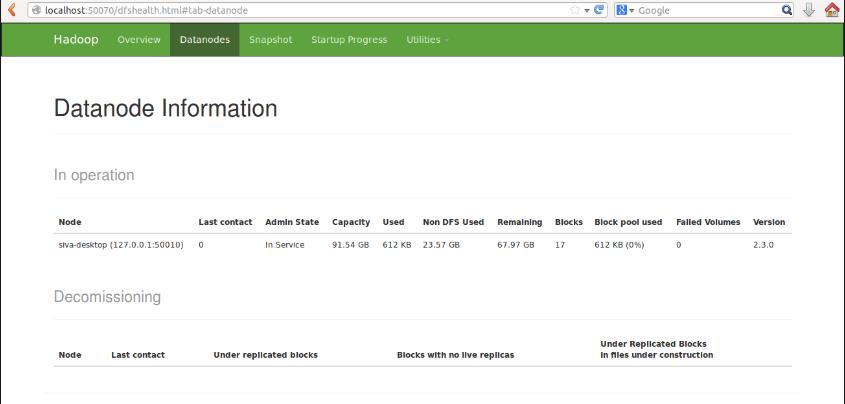
HDFS: Hadoop Distributed File System:
- Significance of HDFS in Hadoop
Features of HDFS
daemons of Hadoop
- 1. Name Node and its functionality
- 2. Data Node and its functionality
- 3. Secondary Name Node and its functionality
- 4. Job Tracker and its functionality
- 5. Task Tracker and its functionality
Data Storage in HDFS
- 1. Introduction about Blocks
- 2. Data replication
Accessing HDFS
- 1. CLI (Command Line Interface) and admin commands
- 2. Java Based Approach
Fault tolerance
Download Hadoop
Installation and set-up of Hadoop
- 1. Start-up & Shut down process
HDFS Federation
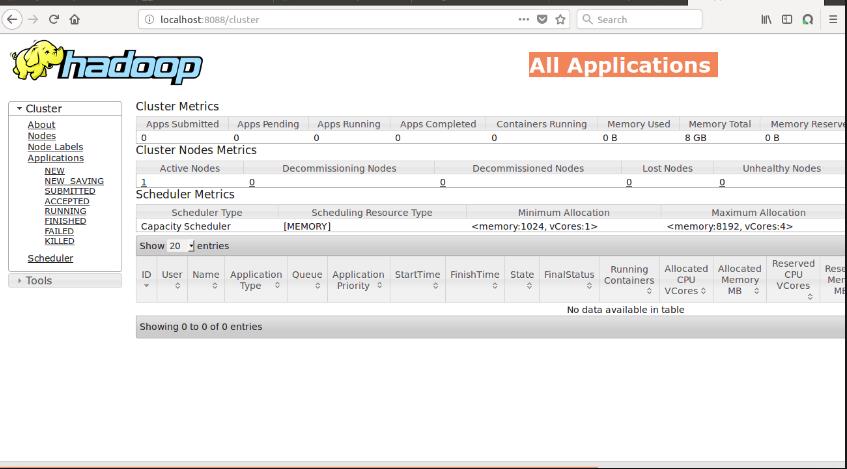
Map Reduce:
- Map Reduce Story
- Map Reduce Architecture
- How Map Reduce works
- Developing Map Reduce
Map Reduce Programming Model
- Different phases of Map Reduce Algorithm.
- Different Data types in Map Reduce.
- how Write a basic Map Reduce Program.
- Driver Code
- 3Mapper
- Reducer
Creating Input and Output Formats in Map Reduce Jobs
- 1. Text Input Format
- 2. Key Value Input Format
- 3. Sequence File Input Format
- Data localization in Map Reduce
- Combiner (Mini Reducer) and Partitioner
- Hadoop I/O
- Distributed cache
PIG:
- Introduction to Apache Pig
- Map Reduce Vs. Apache Pig
- SQL vs. Apache Pig
- Different data types in Pig
- Modes of Execution in Pig
- Grunt shell
- Loading data
- Exploring Pig
- Latin commands
HIVE:
- Hive introduction
- Hive architecture
- Hive vs RDBMS
- HiveQL and the shell
- Managing tables (external vs managed)
- Data types and schemas
- Partitions and buckets
HBASE:
- Architecture and schema design
- HBase vs. RDBMS
- HMaster and Region Servers
- Column Families and Regions
- Write pipeline
- Read pipeline
- HBase commands
Flume
SQOOP
Benefits of getting training
Students, who are interested in building their career in data-based technologies and have a passion to leave a mark in IT field, must go with Hadoop Training course and certification. Considering the fact that these certifications are expensive, one should go for these courses only if they are sure to have complete preparation and skills in this database technology.
Course Outcome
- Store, manage, and analyze unstructured data
- Select the correct big data stores for disparate data sets
- Process large data sets using Hadoop to extract value
- Query large data sets in near real time with Pig and Hive
- Plan and implement a big data strategy for your organization